Paolo Carosone
Main menu:
3D Universal Language
NASA OBELISK
A THREE-DIMENSIONAL UNIVERSAL LANGUAGE TRANSCRIPTION SYSTEM
A project for NASA to be used in space mission communications
by Paolo Carosone and Francesco Antinucci
INTRODUCTION
Human language makes it possible to translate thoughts, mental images, and inner emotional states into a medium that enables us to share them with other people, to "communicate" them. Yet, with all its inexhaustible power of expression, its unlimited flexibility, its infinitely subtle possibility of resolution, language suffers from one major setback. Its natural medium, the spoken word, is extremely volatile: VERBA VOLANT.
Human cultures have, therefore, repeatedly tried to cast language in a more permanent medium that could record its evanescent flux and, until the advent of the taperecorder, this meant translating the non permanent sound distinctions of language into some kind of permanent visual distinctions. Hence the origin of writing: SCRIPTA MANENT.
This is not an easy task, since there is no simple or obvious relation between the articulatory movements of our vocal apparatus or the acoustic phenomena perceived by our ear and the meanings, the thoughts and ideas, they carry. No wonder than that the most primitive transcription systems grasped this relation at the simplest possible level.
They isolated out of the continuous spoken flux the minimal chunk that carried an independent meaning, i.e. the word, and proceeded to give it a physical representation of some form, usually some kind of sketchy drawing that could suggest its meaning.
Each different word was given a different "symbo1" and in this way the so-called "ideographic" writing systems were borne, such as thè original Ancient Egyptian or the Chinese. A purely ideographic writing System is however both clumsy to use and difficult to master. Writing in such a System with even a minimal vocabulary of, say, 2 or 3 thousands words, implies learning to recognize and "draw" 2 or 3 thousands different pictorial elements, and, as a result, the "art" of writing and reading is likely to remain confined to a class of specialists.
The next step (and it was quite a big jump) was to divorce completely the representation of the sounds that make up a language from the meanings they convey. The advantages of taking this step in devising a transcription System are obvious: while there are several thousands of different words in a language, they are all made up of a handful of sounds that recur in different combinations.
If we represent each of these sounds with a symbol, than we will be able to transcribe each word with the combination of symbols corresponding to the sounds the word is made of. In this way we will need only a handful of different symbols. Devising such a System, however, requires a certain degree of abstract analysis, since the spoken chain has to be fragmented into segments that do not correspond to any meaning and whose only relevant property is that of being identical to segments that occur elsewhere in the same spoken chain.
For example, what should be the appropriate length of each such segment?
One solution historically offered was that it should be the smallest chunk of sound chain that can be pronounced by itself: this unit is called the "syllable" {such as, pa ke, ro, u, etc.). If a different graphic symbol is assigned to each of these units, we have a transcription system that is usually called a "syllabic alphabet".
The improvement in terms of learnability, flexibility and practicality of use over an ideographic system is enormous: the number of different syllables making up the sound material of a language ranges between 70 and 100. Writing and reading requires, therefore, the mastering of less than 100 graphic symbols rather than several thousands.
Example of syllabic writing systems are the Japanese kana and the Ethiopian writing of the Amharic language. Once on the way of abstraction it is possible to proceed further in the analysis of the sound material as a basis for transcribing language. In fact, one can notice that even the smallest independently pronounceable segments share common parts among one another, as it happens, for example, among the sounds corresponding to pa, pe, pi, po.
True to say, these parts cannot be pronounced by themselves but only in combination with some other segment C p alone cannot be pronounced, since it is simply a complete occlusion of the vocal tract); they can, however, be "abstracted", thought of, so to speak as recurring units. Once we do this, we are isolating the smallest possible recurring segment of the spoken chain, what is commonly called a "phoneme" or a "phone".
If we now assign a graphic symbol to each of these phonemes, we create a true "alphabetic" transcription system. This system will obviously be much more economical than a syllabic one: any language will do with less than thirty odd symbols. Alphabetic systems, such as the Latin, "Greek, or Cyrillic, are as far as history takes us in the evolution of language transcription systems. Not only they are most economical, but in analyzing the spoken chain into its smallest constituent segments, they also offer us a transparent and systematic representation of the sound structure of a language. Yet, from the point of view of devising an ideal transcription system, alphabetic systems are far from perfect.
They fall short on two ma in counts. First of all, there are systematic relationships even among the smallest segments, the phonemes, that an alphabet fails to express and use in its representation of sounds. For example, p_, b and s, are represented by three different symbols, but p_ and b are related to each other in a much closer way than either of them to s_. In pronouncing both p_ and b the air flux has to be completely stopped and, furthermore, it has to be stopped by the closure of the two lips. In pronouncing s, instead, the air flux must be constricted but not interrupted and, furthermore, the constriction takes place between the tongue and the palate, p, and b are minimally distinct by the fact that in pronouncing b the vocal cords vibrate while they stand still in pronouncing p. As a result p and b "sound" much closer to each other than to s, yet an alphabetic System represents them as three completely different and unanalyzed segments.
The second shortcoming (which is related to the first) is that alphabetic systems are not transparent across languages. The sound represented by t in English is not the same sound that t represents in Italian (in the latter case the tongue touches against the back of the upper teeth, while in the former it touches against the upper gums).
Therefore, even if different languages use the same alphabetic System, we don't know how to pronounce their sounds unless we hear them or somebody teaches us what exactly the graphic signs correspond to.
If we pursue the road of abstraction followed so far one step further, we can find a simultaneous solution to both these inconveniences. It is a step that the cultural history of transcription System has not yet taken, but it is a step that will carry us close to a true ideal transcription System, i.e., one that is completely rational, transparent and universal.
From ideographic to syllabic to alphabetic transcription systems the spoken chain is analyzed into smaller and smaller recurring segments: we have to take this process further. We have to analyze and decompose even the smallest units identified by the alphabetic System. But didn't we say that these were the smallest possible segments recurring in the spoken chain? So how can we go further?
By abstracting from one of the essential properties of language, that of being a temporal sequence. From the point of view of cutting chunks of speech, phonemes are the smallest possible units. But each phoneme is produced by the simultaneous movements and positions of the articulatory organs of speech. Thus if the lips come in close contact and temporarily stop the air flux from the lungs, the sound we perceive is a p, if exactly the same movements take place and at the same time the vocal cords vibrate, than the sound we perceive is a b. If the stopping of the air flux comes from a close contact between the tongue and the back of the upper teeth than the sound generated is that of the Italian t, but if the point of closure is slightly more backward, between the tongue and the upper gums, than the sound produced is that of the English t and if at the same time the vocal cords vibrate than the sound produced is d.
Now suppose that we assign some sort of graphic representation to each of these "articulatory features" and to their simultaneous occurrence; we will then be able to represent all the possible linguistic sounds of the world languages in a completely systematic and transparent way: by looking at their graphic representations everybody will be able to understand and reproduce correctly the sounds. At the same time, relationships among different sounds will be precisely expressed, by the number and type of their constituent features.
In other words, we will have a perfectly rational and ideal transcription System. This is the objective we pursued and
the road we followed in designing the language transcription system which we will now describe.
TRANSCRIPTION SYSTEM
Our system will associate a visual representation to each of the articulatory features that are used in producing speech sounds. In order to do this, we have to specify the list of articulatory features that are needed to produce all the possible linguistic sounds. They divide up into two general classes: those that are used in the formation of "vocalic" sounds and those that are used in the formation of "consonantic" sounds.
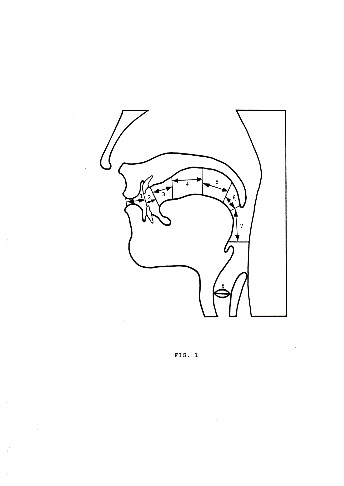
Vocalic sounds are those in whose production the air flux flows freely through thè vocal tract without encountering any closure or friction. Consonantic sounds are those in whose production the flux of air through the vocal tract is partially or totally obstructed by the position of the articulatory organs. The mechanism of sound formation can be better understood with reference to a diagram of the vocal tract, such as that of fig.1
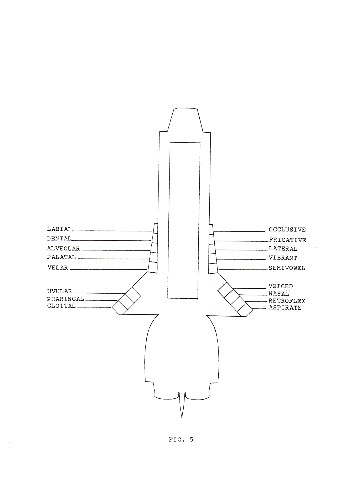
Let us first consider consonantic sounds. Two types of features determine the nature of the obstruction and hence the type of sound produced. They are the place along the vocal tract where the obstruction is situated, the "place of articulation", and the mode in which the obstruction is effected, the "mode of articulation".
In order to specify the place we can divide up the vocal tract into successive segments from the lips to the glottis and assign a feature to each of these segments. In this way we will need 8 such features. The obstruction can take place:
(1) between the two lips or the upper teeth and the lower lip. This feature will be called LABIAL and will belong to the PLACE of articulation series;
(2) between the back of the upper teeth and the tongue. This will be the DENTAL feature and will belong to the PLACE of articulation series;
(3) between the back of the upper gums and the tongue. This will be the ALVEOLAR feature and will belong to the PLACE of articulation series;
(4) between the hard portion of the palatal vault and the tongue. This will be the PALATAL feature and will belong to the PLACE of articulation series;
(5) between the soft portion of the palatal vault and the tongue. This will be the VELAR feature and will belong to the PLACE of articulation series;
(6) between the uvula and the tongue. This will be the UVULAR feature and will belong to the PLACE of articulation series;
(7) between the back of the tongue and the walls of the pharingal cavity. This will be the PHARINGAL feature and will belong to the PLACE of articulation series;
(8) between the two vocal cords . This will be the GLOTTAL feature and will belong to the PLACE of articulation series.
Mode of articulation refers basically to the degree of obstruction effected at each of the possible places of articulation.
We can distinguish 5 such modes and hence specify 5 features belonging to the MODE of articulation series:
(1) OCCLUSIVE, when there is complete obstruction and the air flux is completely stopped;
(2) FRICATIVE, when the contact between the articolatory organs is close but not enough to stop completely the air flux. Thus the passage of the air flux takes place with considerable friction;
(3) LATERAL, when the central part of tongue touches the palate obstructing the vocal tract, but its lateral margins are lowered so that air can flow laterally from both its sides;
(4) VIBRANT, when in obstructing the vocal tract one of the articulatory organ (such as the tip of the tongue) vibrate against the other, thus letting the air pass intermittently;
(5) SEMIVOWEL, when the obstruction is so weak that the articulation can be considered at the very border between that of consonantic sound and that of vocalic sounds, where no- obstruction occurs.
The same articulations described by the PLACE and MODE series of features can be specially modified in the production of some sounds. Accordingly, we will need a third series of features to specify these possible modifications.
This will be the SPECIFIER series and will consist of 4 features:
(1) VOICED, when consonantic sound are produced the vocal cords can either stand still or vibrate producing voice. In the latter case the feature VOICED will be added as a specifier of the articulation;
(2) NASAL, in some cases besides passing through the vocal tract, the air flux can also pass through the nasal cavity, thus conferring a typical "nasal quality" to the sound produced. In these cases the feature NASAL will be added as a specifier of the articulation;
(3) RETROFLEX, when the articulatory organ involved in the articulation is the tip of the tongue, this can sometimes be folded back so that the point of contact with the other articulatory organ is not its upper side but its lower side. In these cases the feature RETROFLEX will be added as a specifier of the articulation;
(4) ASPIRATE, when an OCCLUSIVE articulation is released before the beginning of the following vocalic sound, the passage of a slight and short puff of silent air is produced. In these cases the feature ASPIRATE will be added as a specifier of the articulation.
The simultaneous specification of one of each of these three series of features, PLACE MODE SPECIFIER, will enable us to describe accurately the formation of any consonantic sound.
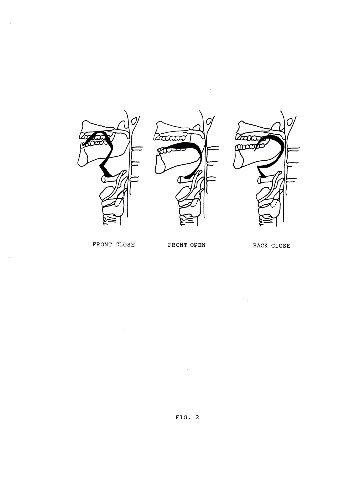
In vocalic sounds the flow of air through the vocal tract in unobstructed. Consequently, the quality of the sounds produced will basically depend on the shape that the vocal cavity can be made to assume. This shape is determined by the position the tongue assumes inside the vocal cavity. These positions can be better understood with reference to the diagrams of fig.2.
The mass of the tongue can move simultaneously along two dimensions: horizontally, by being retracted toward the back of the vocal cavity or extended toward the front (i.e., lips) of the vocal cavity; vertically, by being lowered away or raised toward the palate. Hence, the simultaneous specification of both the horizontal and the vertical position of the tongue will characterize each possible vocalic sound.
Though these articulations are obviously continuous, the specification of the vocalic sounds requires us to distinguish only 3 possible positions along the horizontal dimension and 4 along the vertical one.
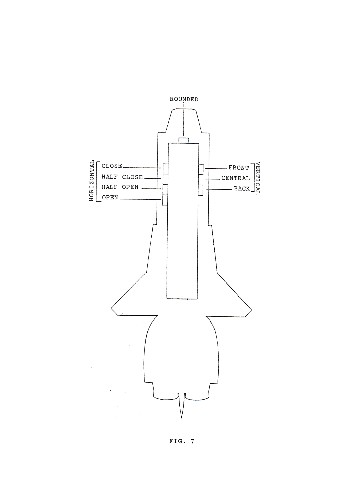
Accordingly we will need the following 3 features belonging to the HORIZONTAL series:
(1) FRONT
(2) CENTRAL
(3) BACK
and the following 4 features belonging to the VERTICAL series:
(1) CLOSE
(2) HALF CLOSE
(3) HALF OPEN
(4) OPEN
(The designation of these feature through the terms "close-open" refers to the fact that the vocal cavity is more and more restricted as the tongue is progressively raised)
Furthermore, in articulating vocal sounds, the two lips can be either flat or rounded. In the latter case an extra feature, ROUNDED, will be added to the feature specifying the articulation.
The simultaneous specification of one of the HORIZONTAL and one of the VERTICAL feature (plus the ROUNDED feature, if needed) will enable us to describe accurately all the vocalic sounds.
VISUAL REPRESENTATION
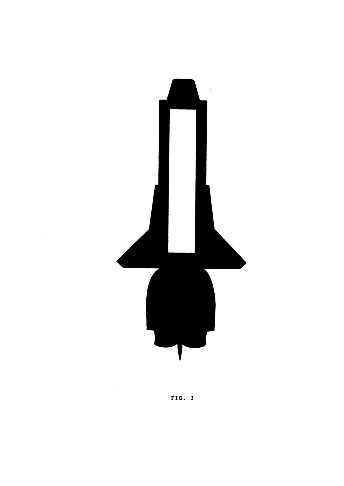
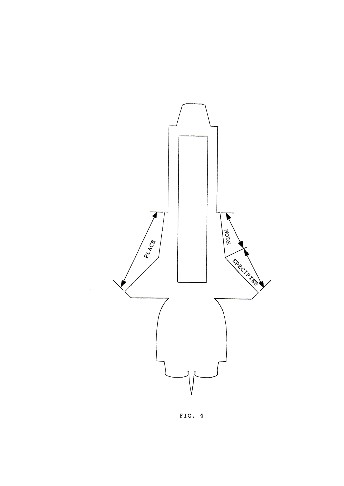
The visual representation of the articulatory features and the way they combine simultaneously in producing a speech sound will be based on systematic modifications of a basic form, that can be realized in any physical medium. The basic form selected for the present project is illustrated in fig.3.
This is a topologically ring-like form that is characterized by an outer and an inner contour. Single features will be expressed as modifications, and, more specifically, segments cut out, of either the outer or the inner contour. A first distinction will be made between consonantic and vocalic sounds. Features pertaining to consonantic sounds will all be represented by cuttings of the outer contour. Features pertaining to the vocalic sounds will all be represented by cuttings of the inner contour.
Three sections of the outer contour will be relevant: one for representing the features of the PLACE series, one for the MODE series and one for the SPECIFIER series, as diagrammed in fig.4.
There are 8 features in the PLACE series, and consequently the contour section allotted to this series will be subdivided into 8 segments, each corresponding to one feature. Specification of a given feature will be represented by cutting out of the contour the segment corresponding to that feature. The same procedure will be followed for the MODE and SPECIFIER series. Hence the allotted contour sections will be subdivided into 5 and 4 segments, respectively. Sections and their segments are diagrammed in fig.5.
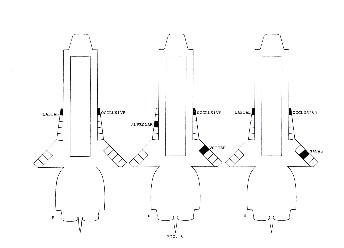
Thus In order to represent a given consonantic sounds the segments of the outer contour corresponding to each of its-constituent features will be cut out. Some sample representations are given in fig.6.
Vocalic sounds will be represented analogously by cuttings of the inner contour of the basic form. On the right hand side of the contour features belonging to the VERTICAL series will be specified, and consequently we will have 4 segments there. On the left, hand side of the contour features belonging to the HORIZONTAL series will be specified, and consequently there will be 3 segments there. The feature ROUNDED will be represented by one segment on the upper side of the contour. Sections and their segments are diagrammed in fig.7.
Fig. 8 shows some sample representations
Combinations of cuttings on either the outer or the inner contour will then represent each possible speech sound. If we want to transcribe actual language through this system, we need now to specify how to represent the sequential combinations of single speech sounds that make up the words and sentences of a language.
On each basic form at most one consonantic sound and one vowel sound can be represented, one on each contour. Let us then establish the following sequential representation rule: if the sequence of sound to be transcribed is either Consonant-Vowel (CV, as for example ta) or Vowel-Consonant (VC, as for example at), then both sounds will be represented on one and the same basic form, by the appropriate cuttings on both the outer and the inner contour.
The two possible orders of this sequence (CV or VC) will be represented by another feature, a segment on the middle o£ the lower side of the inner contour. This segment will be cut off only if the order is VC; if it is left uncut the order will be understood as CV. Fig.9 shows two sample representations of CV and VC orders.
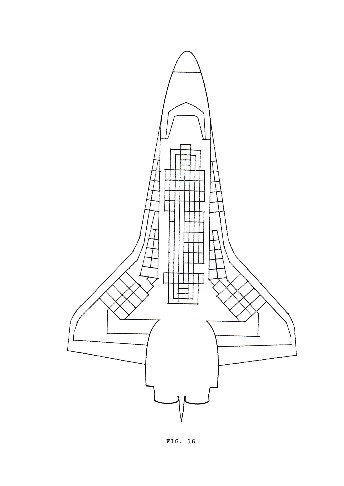
Progressively longer sequences of sounds will be represented by super imposing progressively smaller (scaled down) basic forms, each carrying a CV or VC combination, one on top o£ the other from bottom to top, as diagrammed in fig.10
representing a word, ordered on a plane from either left to right or top to bottom.
For practical purposes (of "readability"."), in the present implementation of the transcription system the height of each block has been limited to a maximum of 4 superimposed layers "of basic forms. Therefore, if the representation of the sounds making up a word takes more than 4 basic forms, the transcription of the word will be divided into more than one block. In these cases we will need a conventional sign on the first block (and also on the second, if more than two are needed) that will indicate that the word being transcribed is not finished yet and its transcription continues on the next block.
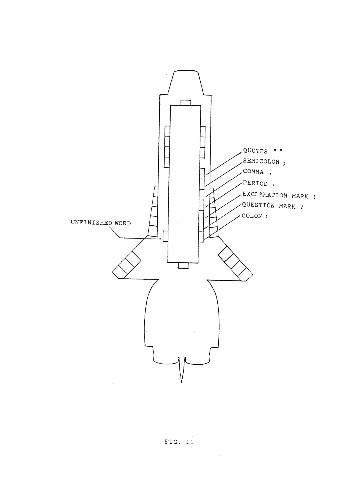
This sign will be a cutting of a segment on the left hand side of the inner contour of the topmost basic form. This segment is indicated in fig.11, under the heading "un finished word".
The remaining segments also indicated in fig. 11 are needed to represent sentence transcription features, such as the comma, the colon, the question marker, etc. They will also be cut out of the topmost layer of the last block immediately preceding the locus of the feature.
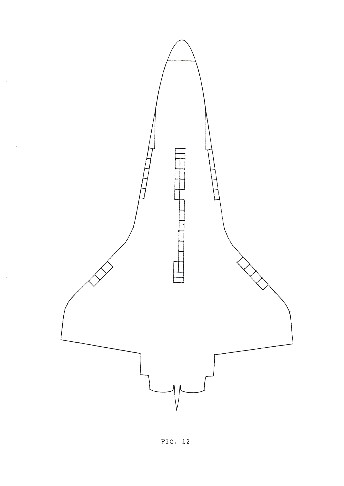
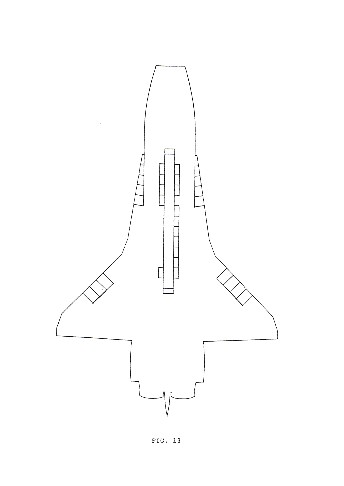
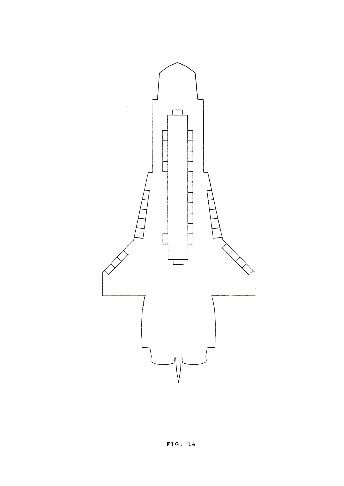
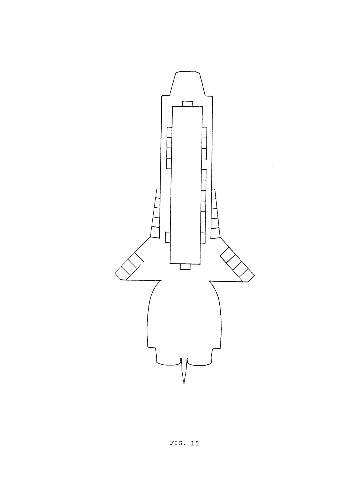
Fig. 12-15 represent the four variations of the basic form corresponding to each of the four layers of a block, from bottom to top.
They are needed in order to scale down the basic form, so that the cuttings on both the inner and the outer contour of each layer will be readable when they are actually superimposed, as diagrammed in fig. 16.